В этой части статьи мы продолжаем рассказывать об итогах 2025 года в плане серверной и настольной виртуализации на базе российских решений. Первую часть статьи можно прочитать тут.
Возможности VDI (виртуализации рабочих мест)
Импортозамещение коснулось не только серверной виртуализации, но и инфраструктуры виртуальных рабочих столов (VDI). После ухода VMware Horizon (сейчас это решение Omnissa) и Citrix XenDesktop российские компании начали внедрять отечественные VDI-решения для обеспечения удалённой работы сотрудников и центрального управления рабочими станциями. К 2025 году сформировался пул новых продуктов, позволяющих развернуть полнофункциональную VDI-платформу на базе отечественных технологий.
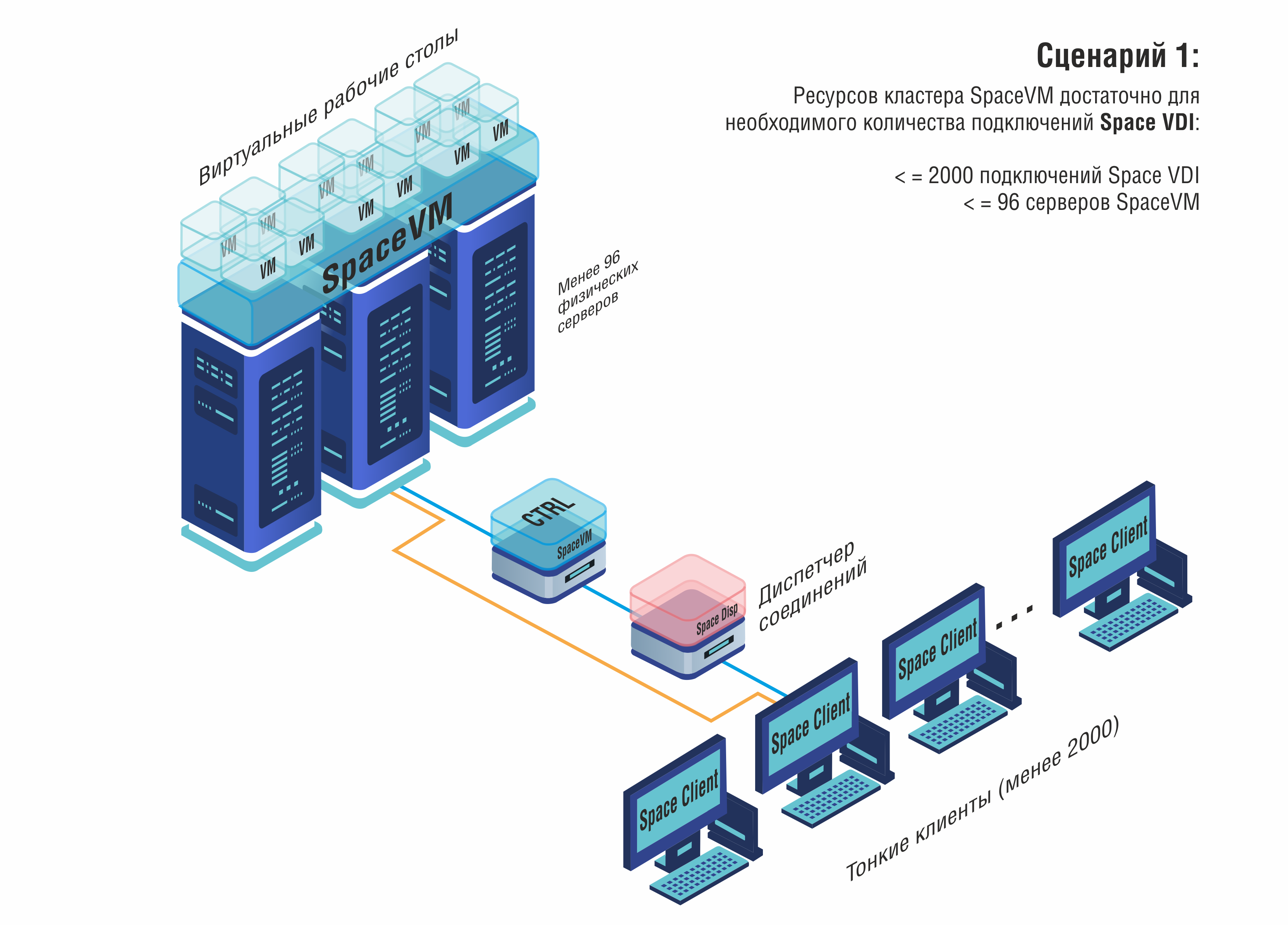
Лидерами рынка VDI стали решения, созданные в тесной связке с платформами серверной виртуализации. Так, компания «ДАКОМ М» (бренд Space) помимо гипервизора SpaceVM предложила продукт Space VDI – систему управления виртуальными рабочими столами, интегрированную в их экосистему. Space VDI заняла 1-е место в рейтинге российских VDI-решений 2025 г., набрав 228 баллов по совокупности критериев.
Её сильные стороны – полностью собственная разработка брокера и агентов (не опирающаяся на чужие open-source) и наличие всех компонентов, аналогичных VMware Horizon: Space Dispatcher (диспетчер VDI, альтернатива Horizon Connection Server), Space Agent VDI (клиентский агент на виртуальной машине, аналог VMware Horizon Agent), Space Client для подключения с пользовательских устройств, и собственный протокол удалённых рабочих столов GLINT. Протокол GLINT разработан как замена зарубежных (RDP/PCoIP), оптимизирован для работы в российских сетях и обеспечивает сжатие/шифрование трафика. В частности, заявляется поддержка мультимедиа-ускорения и USB-перенаправления через модуль Mediapipe, который служит аналогом Citrix HDX. В результате Space VDI предоставляет высокую производительность графического интерфейса и мультимедиа, сравнимую с мировыми аналогами, при этом полностью вписывается в отечественный контур безопасности.
Вторым крупным игроком стала компания HOSTVM с продуктом HostVM VDI. Этот продукт изначально основыван на открытой платформе UDS (VirtualCable) и веб-интерфейсе на Angular, но адаптирован российским разработчиком. HostVM VDI поддерживает широкий набор протоколов – SPICE, RDP, VNC, NX, PCoIP, X2Go, HTML5 – фактически покрывая все популярные способы удалённого доступа. Такая всеядность упрощает миграцию с иностранных систем: например, если ранее использовался протокол PCoIP (как в VMware Horizon), HostVM VDI тоже его поддерживает. Решение заняло 2-е место в отраслевом рейтинге с 218 баллами, немного уступив Space VDI по глубине интеграции функций.
Своеобразный подход продемонстрировал РЕД СОФТ. Их продукт «РЕД Виртуализация» является, в первую очередь, серверной платформой (форком oVirt на KVM) для развертывания ВМ. Однако благодаря тесной интеграции с РЕД ОС и другим ПО компании, Red Виртуализация может использоваться и для VDI-сценариев. Она заняла 3-е место в рейтинге VDI-платформ. По сути, РЕД предлагает создать инфраструктуру на базе своего гипервизора и доставлять пользователям рабочие столы через стандартные протоколы (для Windows-ВМ – RDP, для Linux – SPICE или VNC). В частности, поддерживаются протоколы VNC, SPICE и RDP, что покрывает базовые потребности. Кроме того, заявлена возможность миграции виртуальных машин в РЕД Виртуализацию прямо из сред VMware vSphere и Microsoft Hyper-V, что упрощает переход на решение.
Далее, существуют специализированные отечественные VDI-продукты: ROSA VDI, Veil VDI, Termidesk и др.
ROSA VDI (разработка НТЦ ИТ РОСА) базируется на том же oVirt и ориентирована на интеграцию с российскими ОС РОСА.
Veil VDI – решение компаний «НИИ Масштаб»/Uveon – представляет собственную разработку брокера виртуальных рабочих столов; оно также попало в топ-5 рейтинга.
Termidesk – ещё одна проприетарная система, замыкающая первую шестёрку лидеров. Каждая из них предлагает конкурентоспособные функции, хотя по некоторым пунктам уступает лидерам. Например, Veil VDI и Termidesk пока набрали меньше баллов (182 и 174 соответственно) и, вероятно, имеют более узкую специализацию или меньшую базу внедрений.
Общей чертой российских VDI-платформ является ориентация на безопасность и импортозамещение. Все они зарегистрированы как отечественное ПО и могут применяться вместо VMware Horizon, Citrix или Microsoft RDS. С точки зрения пользовательского опыта, основные функции реализованы: пользователи могут подключаться к своим виртуальным рабочим столам с любых устройств (ПК, тонкие клиенты, планшеты) через удобные клиенты или даже браузер. Администраторы получают централизованную консоль для создания образов ВМ, массового обновления ПО на виртуальных рабочих столах и мониторинга активности пользователей. Многие решения интегрируются с инфраструктурой виртуализации серверов – например, Space VDI напрямую работает поверх гипервизора SpaceVM, ROSA VDI – поверх ROSA Virtualization, что упрощает установку.
Отдельно стоит отметить поддержку мультимедийных протоколов и оптимизацию трафика. Поскольку качество работы VDI сильно зависит от протокола передачи картинки, разработчики добавляют собственные улучшения. Мы уже упомянули GLINT (Space) и широкий набор протоколов в HostVM. Также используется протокол Loudplay – это отечественная разработка в области облачного гейминга, адаптированная под VDI.
Некоторые платформы (например, Space VDI, ROSA VDI, Termidesk) заявляют поддержку Loudplay наряду со SPICE/RDP, чтобы обеспечить плавную передачу видео и 3D-графики даже в сетях с высокой задержкой. Терминальные протоколы оптимизированы под российские условия: так, Termidesk применяет собственный кодек TERA для сжатия видео и звука. В результате пользователи могут комфортно работать с графическими приложениями, CAD-системами и видео в своих виртуальных десктопах.
С точки зрения масштабируемости VDI, российские решения способны обслуживать от десятков до нескольких тысяч одновременных пользователей. Лабораторные испытания показывают, что Space VDI и HostVM VDI могут управлять тысячами виртуальных рабочих столов в распределенной инфраструктуре (с добавлением необходимых серверных мощностей). Важным моментом остаётся интеграция со средствами обеспечения безопасности: многие платформы поддерживают подключение СЗИ для контроля за пользователями (DLP-системы, антивирусы на виртуальных рабочих местах) и могут работать в замкнутых контурах без доступа в интернет.
Таким образом, к концу 2025 года отечественные VDI-платформы покрывают основные потребности удалённой работы. Они позволяют централизованно развертывать и обновлять рабочие места, сохранять данные в защищённом контуре датацентра и предоставлять сотрудникам доступ к нужным приложениям из любой точки. При этом особый акцент сделан на совместимость с российским стеком (ОС, ПО, требования регуляторов) и на возможность миграции с западных систем с минимальными затратами (поддержка разных протоколов, перенос ВМ из VMware/Hyper-V). Конечно, каждой организации предстоит выбрать оптимальный продукт под свои задачи – лидеры рынка (Space VDI, HostVM, Red/ROSA) уже имеют успешные внедрения, тогда как нишевые решения могут подойти под специальные сценарии.
Кластеризация, отказоустойчивость и управление ресурсами
Функциональность, связанная с обеспечением высокой доступности (HA) и отказоустойчивости, а также удобством управления ресурсами, является критичной при сравнении платформ виртуализации. Рассмотрим, как обстоят дела с этими возможностями у российских продуктов по сравнению с VMware vSphere.
Кластеризация и высокая доступность (HA)
Почти все отечественные системы поддерживают объединение хостов в кластеры и автоматический перезапуск ВМ на доступных узлах в случае сбоя одного из серверов – аналог функции VMware HA. Например, SpaceVM имеет встроенную поддержку High Availability для кластеров: при падении хоста его виртуальные машины автоматически запускаются на других узлах кластера.
Basis Dynamix, VMmanager, Red Virtualization – все они также включают механизмы мониторинга узлов и перезапуска ВМ при отказе, что отражено в их спецификациях (наличие HA подтверждалось анкетами рейтингов). По сути, обеспечение базовой отказоустойчивости сейчас является стандартной функцией для любых платформ виртуализации. Важно отметить, что для корректной работы HA требуется резерв мощности в кластере (чтобы были свободные ресурсы для поднятия упавших нагрузок), поэтому администраторы должны планировать кластеры с некоторым запасом хостов, аналогично VMware.
Fault Tolerance (FT)
Более продвинутый режим отказоустойчивости – Fault Tolerance, при котором одна ВМ дублируется на другом хосте в режиме реального времени (две копии работают синхронно, и при сбое одной – вторая продолжает работать без прерывания сервиса). В VMware FT реализован для критичных нагрузок, но накладывает ограничения (например, количество vCPU). В российских решениях прямая аналогия FT практически не встречается. Тем не менее, некоторые разработчики заявляют поддержку подобных механизмов. В частности, Basis Dynamix Enterprise в материалах указывал наличие функции Fault Tolerance. Однако широкого распространения FT не получила – эта технология сложна в реализации, а также требовательна к каналам связи. Обычно достаточен более простой подход (HA с быстрым перезапуском, кластерные приложения на уровне ОС и т.п.). В критических сценариях (банковские системы реального времени и др.) могут быть построены решения с FT на базе метрокластеров, но это скорее штучные проекты.
Снапшоты и резервное копирование
Снимки состояния ВМ (snapshots) – необходимая функция для безопасных изменений и откатов. Все современные платформы (zVirt, SpaceVM, Red и прочие) поддерживают создание мгновенных снапшотов ВМ в рабочем состоянии. Как правило, доступны возможности делать цепочки снимков, однако требования к хранению диктуют, что постоянно держать много снапшотов нежелательно (как и в VMware, где они влияют на производительность). Для резервного копирования обычно предлагается интеграция с внешними системами бэкапа либо встроенные средства экспорта ВМ.
Например, SpaceVM имеет встроенное резервное копирование ВМ с возможностью сохранения бэкапов на удалённое хранилище. VMmanager от ISPsystem также предоставляет модуль бэкапа. Тем не менее, организации часто используют сторонние системы резервирования – здесь важно, что у российских гипервизоров обычно открыт API для интеграции. Почти все продукты предоставляют REST API или SDK, позволяющий автоматизировать задачи бэкапа, мониторинга и пр. Отдельные вендоры (например, Basis) декларируют принцип API-first, что упрощает связку с оркестраторами резервного копирования и мониторинга.
Управление ресурсами и балансировка
Мы уже упоминали наличие аналогов DRS в некоторых платформах (автоматическое перераспределение ВМ). Кроме этого, важно, как реализовано ручное управление ресурсами: пулы CPU/памяти, приоритеты, квоты. В VMware vSphere есть ресурсные пулы и shares-приоритеты. В российских системах подобные механизмы тоже появляются. zVirt, например, позволяет объединять хосты в логические группы и задавать политику размещения ВМ, что помогает распределять нагрузку. Red Virtualization (oVirt) исторически поддерживает задание весов и ограничений на ЦП и ОЗУ для групп виртуальных машин. В Basis Dynamix управление ресурсами интегрировано с IaC-инструментами – можно через Terraform описывать необходимые ресурсы, а платформа сама их выделит.
Такое тесное сочетание с DevOps-подходами – одно из преимуществ новых продуктов: Basis и SpaceVM интегрируются с Ansible, Terraform для автоматического развертывания инфраструктуры как кода. Это позволяет компаниям гибко управлять ИТ-ресурсами и быстро масштабировать кластеры или развертывать новые ВМ по шаблонам.
Управление кластерами
Центральная консоль управления кластером – обязательный компонент. Аналог VMware vCenter в отечественных решениях присутствует везде, хотя может называться по-разному. Например, у Space – SpaceVM Controller (он же выполняет роль менеджера кластера, аналог vCenter). У zVirt – собственная веб-консоль, у Red Virtualization – знакомый интерфейс oVirt Engine, у VMmanager – веб-панель от ISPsystem. То есть любой выбранный продукт предоставляет единый интерфейс для управления всеми узлами, ВМ и ресурсами. Многие консоли русифицированы и достаточно дружелюбны. Однако по отзывам специалистов, удобство администрирования ещё требует улучшений: отмечается, что ряд операций в отечественных платформах более трудоёмкие или требуют «танцев с бубном» по сравнению с отлаженным UI VMware. Например, на Хабре приводился пример, что создание простой ВМ в некоторых системах превращается в квест с редактированием конфигурационных файлов и чтением документации, тогда как в VMware это несколько кликов мастера создания ВМ. Это как раз то направление, где нашим решениям ещё есть куда расти – UX и простота администрирования.
В плане кластеризации и отказоустойчивости можно заключить, что функционально российские платформы предоставляют почти весь минимально необходимый набор возможностей. Кластеры, миграция ВМ, HA, снапшоты, бэкап, распределенная сеть, интеграция со сториджами – всё это реализовано (см. сводную таблицу ниже). Тем не менее, зрелость реализации зачастую ниже: возможны нюансы при очень крупных масштабах, не все функции могут быть такими же «отполированными» как у VMware, а администрирование требует большей квалификации.
Платформа
Разработчик
Технологическая основа
Особенности архитектуры
Ключевые сильные стороны
Известные ограничения
Basis Dynamix
БАЗИС
Собственная разработка (KVM-совместима)
Классическая и гибридная архитектура (есть Standard и Enterprise варианты)
Высокая производительность, интеграция с Ansible/Terraform, единая экосистема (репозиторий, поддержка); востребован в госсекторе.
Мало публичной информации о тонкостях; относительно новый продукт, требует настройки под задачу.
SpaceVM
ДАКОМ M (Space)
Проприетарная (собственный стек гипервизора)
Классическая архитектура, интеграция с внешними СХД + проприетарные HCI-компоненты (FreeGRID, SDN Flow)
Максимально функциональная платформа: GPU-виртуализация (FreeGRID), своя SDN (аналог NSX), полный VDI-комплекс (Space VDI) и собственные протоколы; высокое быстродействие.
Более сложное администрирование (богатство функций = сложность настроек).
zVirt
Orion soft
Форк oVirt (KVM) + собственный бэкенд
Классическая модель, SDN-сеть внутри (distributed vSwitch)
Богатый набор функций: микросегментация сети SDN, Storage Live Migration, авто-балансировка ресурсов (DRS-аналог), совместим с открытой экосистемой oVirt; крупнейшая инсталляционная база (21k+ хостов ожидается).
Проблемы масштабируемости на очень больших кластерах (>50 узлов); интерфейс менее удобен, чем VMware (выше порог входа).
Red Виртуализация
РЕД СОФТ
Форк oVirt (KVM)
Классическая схема, тесная интеграция с РЕД OS и ПО РЕД СОФТ
Знакомая VMware-подобная архитектура; из коробки многие функции (SAN, HA и др.); сертификация ФСТЭК РЕД ОС дает базу для безопасности; успешные кейсы миграции (Росельхозбанк, др.).
Более ограниченная экосистема поддержки (сильно завязана на продукты РЕД); обновления зависят от развития форка oVirt (нужны ресурсы на самостоятельную разработку).
vStack HCP
vStack (Россия)
FreeBSD + bhyve (HCI-платформа)
Гиперконвергентная архитектура, собственный легковесный гипервизор
Минимальные накладные расходы (2–5% CPU), масштабируемость «без ограничений» (нет фикс. лимитов на узлы/ВМ), единый веб-интерфейс; независим от Linux.
Относительно новая/экзотичная технология (FreeBSD), сообщество меньше; возможно меньше совместимых сторонних инструментов (бэкап, драйверы).
Cyber Infrastructure
Киберпротект
OpenStack + собственные улучшения (HCI)
Гиперконвергенция (Ceph-хранилище), поддержка внешних СХД
Глубокая интеграция с резервным копированием (наследие Acronis), сертификация ФСТЭК AccentOS (OpenStack), масштабируемость для облаков; работает на отечественном оборудовании.
Менее подходит для нагрузок, требующих стабильности отдельной ВМ (особенности OpenStack); сложнее в установке и сопровождении без экспертизы OpenStack.
Другие (ROSA, Numa, HostVM)
НТЦ ИТ РОСА, Нума Техн., HostVM
KVM (oVirt), Xen (xcp-ng), KVM+UDS и др.
В основном классические, частично HCI
Закрывают узкие ниши или предлагают привычный функционал для своих аудиторий (например, Xen для любителей XenServer, ROSA для Linux-инфраструктур). Часто совместимы с специфическими отечественными ОС (ROSA, ALT).
Как правило, менее функционально богаты (ниже баллы рейтингов); меньшая команда разработки = более медленное развитие.
Компания VMware недавно объявила о первом результате теста VMmark 4 с использованием последнего релиза платформы виртуализации VMware Cloud Foundation (VCF) 9.0. Метрики, показанные системой Lenovo, также стали первым результатом тестирования новейшей 4-сокетной системы на базе процессора Intel Xeon серии 6700 с технологией Performance-cores, который обеспечивает большее количество ядер и более высокую пропускную способность памяти. Итоговый результат доступен на странице VMmark 4 Results.
В следующей таблице приведено сравнение нового результата Lenovo с системой предыдущего поколения ThinkSystem под управлением vSphere 8.0 Update 3:
График показывает рост общего количества ядер на 43% между этими двумя результатами:
С точки зрения очков производительности, показатель VMmark 4 вырос на 49%:
Ключевые моменты:
Сочетание VCF 9.0 и нового серверного оборудования позволило запустить на 50% больше виртуальных машин / рабочих нагрузок (132) по сравнению с результатом предыдущего поколения (88 ВМ).
Процессоры Intel Xeon 6788P в Lenovo ThinkSystem SR860 V4 имеют на 43% больше ядер, чем процессоры предыдущего поколения Intel Xeon Platinum 8490H в ThinkSystem SR860 V3
Показатель VMmark на 49% выше, чем результат VMmark 4 для предыдущего поколения.
VMmark — это бесплатный инструмент тестирования, который используется партнёрами и клиентами для оценки производительности, масштабируемости и энергопотребления платформ виртуализации. Посетите страницу продукта VMmark и сообщество VMmark Community, чтобы узнать больше. Также вы можете попробовать VMmark 4 прямо сейчас через VMware Hands-on Labs Catalog, выполнив поиск по запросу «VMmark».
Наш постоянный читатель Сергей обратил внимание на статью Michael Schroeder о том, куда переехали основные онлайн-ресурсы VMware после интеграции с Broadcom.
1. Техническая документация
C 1 января 2025 года техническая документация сайта docs.vmware.com была перемещена на ресурс techdocs.broadcom.com:
Этот сайт содержит не только документацию по продуктам VMware, но и по другим решениям Broadcom. Сайт жутко неудобен, продукты надо как-то искать в поисковой строке, при этом в результатах не всегда можно найти то, что было нужно. Также ранее для документации VMware был доступен экспорт статьи в PDF, теперь же эта возможность отсутствует.
2. Максимумы конфигурации
Сайт configmax.vmware.com переехал на ресурс compatibilityguide.broadcom.com. Тут вроде все как прежде, ничего пока не поломали:
3. Списки совместимости оборудования (HCL)
Списки VMware Hardware Compatibility Lists (HCL) теперь располагаются по адресу compatibilityguide.broadcom.com. Тут в принципе выглядит это все неплохо:
4. Технический ресурс VMware Core
Один из самых полезных ресурсов VMware Core (core.vmware.com) компания Broadcom просто прикончила - теперь по этой ссылке редиректит по адресу vmware.com/resources/resource-center. На этом ресурсе теперь хрен что найдешь - раздел поиска неинтуитивен. Сейчас хоть поправили названия продуктов, а то раньше вместо NSX надо было искать в категории "Networking by NSX", а vSAN - в разделе "Storage by vSAN".
5. Ресурс для разработчиков
Сайт code.vmware.com теперь находится по адресу community.broadcom.com/vmware-code/home. Тут тоже выглядит все как-то аляповато, но про детали могут рассказать только сами разработчики:
Для прошедших конференций Explore 2024 в Лас-Вегасе и Барселоне компания VMware составила список из главных лабораторных работ, которые были востребованы среди ИТ-специалистов. Вот они:
Топ-10 hands-on labs (HoL) в Лас-Вегасе:
Топ-10 hands-on labs в Барселоне:
Также совсем недавно были представлены новые лабораторные работы:
Ознакомьтесь с новыми функциями vSphere 8: параллельный патчинг, улучшенное управление ресурсами, усовершенствования для гостевых ОС и рабочих нагрузок, а также "зеленые" метрики.
Изучите VMware Cloud Foundation в деталях: пользователи узнают, как настраивать, управлять и поддерживать гиперконвергентную инфраструктуру с помощью SDDC Manager от VMware. Лабораторная работа включает обзор Cloud Foundation, управление жизненным циклом, операции с доменами рабочих нагрузок, управление сертификатами и паролями. Вы получите полное представление о возможностях VMware Cloud Foundation и практический опыт работы с его компонентами и инструментами.
Погрузитесь в выполнение задач Day-2, лучшие практики и эффективные операции. Все будет проходить в режиме пошагового сопровождения, поэтому ваши базовые знания vSphere будут полезны.
Советы по оптимизации производительности vSphere 8.0 в разных аспектах, а также информация о том, как правильно масштабировать виртуальные машины под конкретную среду для наиболее эффективного использования ресурсов.
Начните работу с платформой NSX. VMware покажет администраторам, как задавать сетевые параметры и настройки безопасности. Это включает в себя создание логических сегментов, логических маршрутизаторов и управление связанными параметрами безопасности.
Проверьте свои навыки работы с vSphere в процессе игры Odyssey! Узнайте, какое место вы занимаете в глобальном рейтинге ИТ-специалистов в области виртуализации.
Недавно мы писали о том, что команда ESXi-Arm выпустила новую версию популярной платформы виртуализации ESXi-Arm Fling (v2.0) (ссылка на скачивание тут), которая теперь основана на базе кода ESXi версии 8.x и конкретно использует последний релиз ESXi-x86 8.0 Update 3b.
Вильям Лам рассказал о том, что теперь вы можете запустить экземпляр ESXi-Arm V2 внутри виртуальной машины, что также называется Nested ESXi-Arm. На конференции VMware Explore в США он использовал Nested ESXi-Arm, так как у него есть ноутбук Apple M1, и ему нужно было провести демонстрацию для сессии Tech Deep Dive: Automating VMware ESXi Installation at Scale, посвященной автоматизированной установке ESXi с помощью Kickstart. Поскольку и ESXi-x86, и ESXi-Arm имеют одинаковую реализацию, возможность запуска Nested ESXi-Arm оказалась полезной (хотя он использовал версию, отличающуюся от официального релиза Fling). Такой же подход может быть полезен, если вы хотите запустить несколько виртуальных машин ESXi-Arm для изучения API vSphere и подключить Nested ESXi-Arm к виртуальной машине x86 VCSA (vCenter Server Appliance). Возможно, вы разрабатываете что-то с использованием Ansible или Terraform - это действительно открывает множество вариантов для тех, у кого есть такая потребность.
Arm Hardware
Так же как и при создании Nested ESXi-x86 VM, выберите опцию типа ВМ "Other" (Другое) и затем выберите "VMware ESXi 8.0 or later", настроив как минимум на 2 виртуальных процессора (vCPU) и 8 ГБ оперативной памяти.
Примечание: Текущая версия ESXi-Arm НЕ поддерживает VMware Hardware-Assisted Virtualization (VHV), которая необходима для запуска 64-битных операционных систем в Nested или внутренних виртуальных машинах. Если вы включите эту настройку, запустить Nested ESXi-Arm VM не получится, поэтому убедитесь, что эта настройка процессора отключена (по умолчанию она отключена).
VMware Fusion (M1 и новее)
Еще одна хорошая новость: для пользователей Apple Silicon (M1 и новее) теперь также можно запускать виртуальные машины Nested ESXi-Arm! Просто выберите «Other» (Другое), затем тип машины «Other 64-bit Arm» и настройте ВМ с как минимум 2 виртуальными процессорами (vCPU) и 8 ГБ оперативной памяти. Вильяму как раз потребовалась эта возможность на VMware Explore, когда он демонстрировал вещи, не связанные напрямую с архитектурой Arm. Он попросил команду инженеров предоставить внутреннюю сборку ESXi-Arm, которая могла бы работать на Apple M1, теперь же эта возможность ESXi-Arm доступна для всех.
Примечание: поскольку для работы Nested-ESXi-Arm требуется режим promiscuous mode, при включении виртуальной машины в VMware Fusion вас могут раздражать запросы на ввод пароля администратора. Если вы хотите отключить эти запросы, ознакомьтесь с этой статьей в блоге для получения дополнительной информации.
6 мая 2024 года завершился переходный этап "Day-2", в ходе которого бэкенд-система VMware была полностью смигрирована на бэкенд-систему Broadcom. На эту тему почитайте наш пост о переезде сообществ VMware в Broadcom Community (а также о переезде Flings из раздела VMware Labs).
Однако может потребоваться еще несколько недель, чтобы все новые сервисы полностью стабилизировались после такого масштабного проекта переезда. Также запланированы некоторые обновления после миграции для некоторых веб-ресурсов, так что к концу месяца можно ожидать дополнительных обновлений.
В связи с изменениями в большом количестве веб-сайтов VMware, включая прекращение поддержки некоторых из них или полное сохранение без изменений, Вильям Лам собрал различные ссылки, которые могут быть полезны для клиентов, партнеров и сотрудников VMware. Вильям продолжит обновлять эту страницу по мере поступления новой или обновленной информации, поэтому не забудьте добавить ее в закладки, чтобы быть в курсе последних новостей.
Примечание: для некоторых загрузок потребуются права доступа к контенту (например, вы участвуете в бета-программе), в то время как для других будет достаточно учетной записи. Вы можете проверить это позже на этой неделе, так как не все загрузки могут быть доступны сразу.
Недавно в компании VMware решили несколько переработать состав доступных онлайн лабораторных работ Hands-On Labs (HoL), включив туда новый контент в соответствии с последними изменениями в продуктовой линейке, а также убрав уже не актуальные лабы. Напомним, что полный список доступных онлайн лабораторных работ доступен по этой ссылке. А о прошлом пакете новых работ HoL мы писали вот тут.
Сейчас в списке находятся 103 лабы:
Давайте посмотрим, какие новые HoL появились на начало этого года:
Дункан Эппинг поднял вопрос о том, необходимо ли указывать 2 параметра Isolation Address в растянутом кластере VMware vSAN (stretched cluster), которые используются механизмом VMware HA.
Вопрос всплыл в связи с документацией по vSAN, где говорится о том, что вам нужно иметь 2 адреса на случай изоляции кластера в целях разумной избыточности:
Некоторые пользователи спрашивали, могут ли они использовать один Gateway Address от Cisco ACI, который будет доступен в обоих местах, даже если произойдет разделение, например, из-за сбоя ISL. Если это действительно так, и IP-адрес действительно доступен в обоих местах во время таких сбоев, то достаточно использовать один IP-адрес в качестве адреса изоляции.
Тем не менее, вам нужно удостовериться, что IP-адрес пингуется через сеть vSAN при использовании vSAN в качестве платформы для расширенного хранения данных. Ведь когда vSAN активирован, vSphere HA использует именно сеть vSAN для управляющих сигналов. Если адрес пингуется, вы можете просто задать адрес изоляции, установив расширенную настройку "das.isolationaddress0". Также рекомендуется отключить использование стандартного шлюза управляющей сети, установив "das.usedefaultisolationaddress" в значение false для сред, использующих vSAN в качестве платформы.
Пару дней назад мы писали о новом пользовательском интерфейсе лабораторных работ Hands-On Labs, который появился на HoL портале VMware. Сегодня мы расскажем о том, какие лабы стали доступны для пользователей в этом году, а также о тех лабах, которые были заменены на их более актуальные версии.
Компания VMware на днях обновила интерфейс своих онлайн-лабораторных работ для технических специалистов VMware Hands-On Labs. Давайте посмотрим, что нового в переработанном UI:
1. Упрощенная навигация и улучшенное обнаружение элементов
Теперь вы можете легко сортировать лабы по имени или давности и фильтровать их по каталогам, продуктам, тегам или бейджам. Найти вашу идеальную лабораторную стало еще проще!
2. Современный дизайн
Построенный на общей для многих продуктов VMware системе Clarity, обновленный интерфейс не только выглядит хорошо, но и приносит ощущение единства с остальными продуктами экосистемы VMware.
3. Функция "Избранное"
По многочисленным запросам пользователей, теперь вы можете отмечать лаборатории как "Избранные", что делает возврат к особенно полезным или интересным лабораториям быстрым и легким.
4. Улучшенный поиск и индексация
Алгоритмы поиска были оптимизированы и теперь обеспечивают более быстрый и точный поиск того, что вы ищете. Улучшенная индексация позволяет получать мгновенный доступ к контенту, отображаемому с помощью фильтров и сортировок.
Таким образом, следствием улучшений интерфейса Hands-On Labs будет:
Улучшение вашего образовательного опыта - это не просто косметическое обновление. Улучшения направлены на повышение качества образовательного процесса, что делает его более интуитивным и интерактивным. Новый дизайн предназначен для того, чтобы помочь вам эффективно переключаться между различными лабораторными работами, позволяя больше сосредоточиться на обучении, а не на выяснении того, как все это работает.
Консистентность на всех платформах - интерфейс Hands-on Labs приводится в соответствие с другими продуктами VMware, в итоге получается бесшовный опыт, независимо от того, какие инструменты вы используете.
Доступность - современный интерфейс предлагает улучшенные функции доступности, обеспечивая инклюзивную образовательную среду для всех.
Задел на будущее - с этими обновлениями VMware заложила основу для новых функций и возможностей, которые вы увидите в ближайшие месяцы.
Получить доступ к виртуальным тестовым лабораториям VMware Hands-on Labs можно по этой ссылке.
Дункан Эппинг в своем блоге описал ситуацию, когда один из администраторов распределенного кластера vSAN увидел множество сообщений об ошибках, говорящих о том, что vSphere HA не мог перезапустить определенную виртуальную машину во время сбоя межсайтового соединения ISL.
Бывает это в следующей типовой конфигурации кластера vSAN:
Предположим, что Datacenter A - это "preferred site", а Datacenter B - это "secondary site". Если между датацентром A и датацентром B происходит сбой ISL, компонент Witness, находящийся на третьей площадке, автоматически привяжет себя к датацентру A. Это означает, что ВМ в датацентре B потеряют доступ к хранилищу данных vSAN.
С точки зрения кластера HA, у датацентра A всегда будет Primary-узел (ранее он назывался Master), он же есть и у датацентра B. Первичный узел обнаружит, что есть некоторые ВМ, которые больше не работают, и он попытается перезапустить их. Он попытается сделать это на обеих площадках, и конечно, сайт, где доступ к хранилищу данных vSAN потерян, увидит, что перезапуск не удался.
А вот и важный момент, в зависимости от того, где/как сервер vCenter подключен к этим площадкам. Он может получать, а может и нет информацию об успешных и неудачных перезапусках. Иногда бывают ситуации (в зависимости от архитектуры и характера сбоя), когда сервер vCenter может общаться только с primary-узлом в датацентре B, и это приводит к сообщениям о неудачных попытках перезапуска, хотя на самом деле все ВМ были успешно перезапущены в датацентре A.
В этом случае интерфейс может дать разъяснение - он даст вам информацию о том, какой узел является первичным, и также сообщит вам о либо об "изоляции сети" (network isolation) или о "разделении сети" (network partition) в соответствующих разделах разделах панели Hosts. При сбое ISL - это, конечно же, разделение сети.
На прошедшей осенью этого года главной конференции о виртуализации Explore 2022 компания VMware сделала немало интересных анонсов, главным из которых стал выпуск новых версий платформ vSphere 8 и vSAN 8. На американской и европейской конференциях много говорили о будущих новых продуктах и технологиях VMware, но несколько незамеченным остался переход VMware на новую схему релизов платформы vSphere...
Некоторое время назад мы писали о службах VMware vSphere Cluster Services (ранее они назывались Clustering Services), которые появились в VMware vSphere 7 Update 1. Они позволяют организовать мониторинг доступности хостов кластера vSphere, без необходимости зависеть от служб vCenter. Для этого VMware придумала такую штуку - сажать на хосты кластера 3 служебных агентских виртуальных машины, составляющих vCLS Control Plane, которые отвечают за доступность кластера в целом:
Надо отметить, что эти службы обязательны для функционирования механизма динамической балансировки нагрузки в кластере VMware DRS. Если вы выключите одну из виртуальных машин vCLS, то увидите предупреждение о том, что DRS перестанет функционировать:
Иногда требуется отключить службы Cluster Services, что может оказаться необходимым в следующих случаях:
Вам нужно правильно удалить кластер HA/DRS и выполнить корректную последовательность по выводу его из эксплуатации
Требуется удалить / пересоздать дисковые группы VMware vSAN, на хранилищах которых размещены виртуальные машины vCLS
Вам не требуется использовать DRS, и вы хотите отключить эти службы. В этом случае помните, что механизм обеспечения отказоустойчивости VMware HA также будет функционировать некорректно. Он зависит механизма балансировки нагрузки при восстановлении инфраструктуры после сбоя - именно на DRS он полагается при выборе оптимальных хостов для восстанавливаемых виртуальных машин.
Режим, в котором службы Cluster Services отключены, называется Retreat Mode. Итак, заходим в vSphere Client и выбираем кластер, в котором мы хотим ввести Retreat Mode. В строке браузера нам нужна строка вида:
domain ID domain-c<number>
Скопировав эту часть строчки, идем в Advanced Setting сервера vCenter и нажимаем Edit Settings:
Далее создаем там параметр со следующим именем и значением false:
config.vcls.clusters.domain-cxxx.enabled
Где cxxx - это идентификатор домена, который вы скопировали на прошлом шаге:
После этого нажимаем кнопку Save. В консоли vSphere Client в разделе vCLS для кластера мы увидим, что этих виртуальных машин больше нет:
На вкладке Summary мы увидим предупреждение о том, что vSphere Cluster Services больше не работает, а службы DRS вследствие этого также не функционируют корректно:
Чтобы вернуть все как было, нужно просто удалить добавленный параметр из Advanced Settings сервера vCenter.
Как вы знаете, у компании VMware есть портал лабораторных работ Hands-on-Labs (HoL), где в онлайн-формате доступна работа с интерфейсом различных продуктов в целях тренировки выполнения практических задач. При этом все это абсолютно бесплатно и не требует ничего устанавливать ни на сервер, ни на свою рабочую станцию - все происходит в окне браузера.
Напомним, что продукт Log Insight предназначен для аналитики лог-файлов и мониторинга инфраструктуры в частных и публичных облаках. Сама лабораторная работа предназначена для новичков и содержит следующие модули:
Getting to Know Log Insight – Walk Through
Understanding Querying and Alerting Within Log Insight
Content Packs, How to Make Log Insight More Powerful
Log Insight Agent
Log Insight Cloud – A SaaS Version of Log Insight
Для каждого этапа доступен мануал с детальным описанием шагов и задач, стоящих перед пользователем в рамках предлагаемых вариантов использования продукта.
Вот так выглядит работа с дэшбордами (активные области подсвечиваются):
А так - со средствами интерактивной аналитики:
Для тех, кто освоил первые шаги с продуктом vRealize Log Insight, доступны следующие лабораторные и расширенная информация по данному решению от VMware:
Компания Principled Technologies выпустила интересное сравнение производительности в контексте плотности размещения виртуальных машин на сервере (VM Density), которое показывает превосходство гипервизора VMware vSphere 7 Update 2 над открытой архитектурой Red Hat OpenShift версии 4.9.
Для тестирования использовались виртуальные машины с полезной нагрузкой SQL Server. С точки зрения оборудования использовался кластер из 5 одинаковых серверов HPE ProLiant DL380 Gen 10, где были размещены ВМ, также для OpenShift дополнительно использовались еще 3 хоста как управляющие узлы.
Первый результат теста - это максимальное число активных виртуальных машин на один узел, которые можно было разместить при обеспечении определенного уровня производительности SQL Server. Тут результат 14-30 в пользу платформы VMware vSphere 7 Update 2:
Также создавали простаивающие виртуальные машины и смотрели, какое их максимальное количество можно разместить на одном хосте, тут тоже vSphere далеко впереди:
В исследовании отдельно подчеркивается, что VMware vSphere имеет также следующие преимущества:
Механизм обеспечения высокой доступности VMware HA работает более эффективно и проще настраивается
Рутинные задачи (Day-2) на платформе VMware vSphere выполнять удобнее и быстрее
Для хостов ESXi можно делать апгрейд хостов без их перезагрузки
Мы много пишем про растянутые кластеры VMware vSAN Stretched Clusters для онпремизной инфраструктуры VMware vSphere, но не особо затрагивали тему растянутых кластеров в публичных облаках. В частности, в инфраструктуре VMware Cloud on AWS можно создавать такие кластеры, работающие на уровне зон доступности (Availability Zones).
Облачные администраторы знают, что публичное облако AWS разделено на регионы (Regions), в рамках которых есть зоны доступности (Availability Zones, AZ), представляющие собой домены отказа (аналогичные таковым в vSAN). То есть если произойдет сбой (что довольно маловероятно), он затронет сервисы только одной зоны доступности, остальные AZ этого региона продолжат нормально функционировать.
Сама Amazon рекомендует дублировать критичные сервисы на уровне разных зон доступности, а с помощью растянутых кластеров VMware vSAN можно сделать полноценную задублированную среду на уровне AZ в рамках одного региона с компонентом Witness для защиты от ситуации Split-brain, когда будет разорвана коммуникация между зонами:
Для такой конфигурации вам потребуется создать SDDC с поддержкой Stretched Cluster, который создается на этапе настройки SDDC на платформе VMC on AWS. Надо понимать, что при развертывании SDDC можно задать тип кластера Standard или Stretched, который уже нельзя будет поменять в дальнейшем.
Пользователь задает AWS Region, тип хоста, имя SDDC и число хостов, которые он хочет развернуть. Далее администратор выбирает аккаунт AWS и настраивает VPC-подсеть, привязывая ее к логической сети для рабочих нагрузок в аккаунте. Нужно выбрать 2 подсети для обслуживания двух зон доступности. Первая устанавливается для preferred-площадки vSAN, а вторая помечается как сеть для "non-preferred" сайта.
После создания кластера, когда вы зайдете в инстанс Multi-AZ SDDC vCenter вы увидите растянутый кластер vSAN с одинаковым числом узлов на каждой из AZ и один компонент Witness, находящийся за пределами данных AZ.
Такая конфигурация работает как Active-Active, то есть вы можете помещать производственные виртуальные машины в каждую из зон, но вам нельзя будет использовать более 50% дисковой емкости для каждой из облачных площадок.
Конечно же, нужно позаботиться и о защите виртуальных машин как на уровне площадки, так и на уровне растянутого кластера. Лучше всего использовать политику хранения "Dual site mirroring (stretched cluster)" на уровне ВМ. В этом случае при сбое виртуальной машины в рамках одной зоны доступности она будет автоматически перезапущена в другой AZ с помощью механизма VMware HA.
Также администратору надо контролировать физическое размещение виртуальных машин по площадкам, а также политику Failures to tolerate (FTT):
Конечно же, не все виртуальные машины нужно реплицировать между площадками - иначе вы просто разоритесь на оплату сервисов VMConAWS. Администратор должен выставить правила site affinity rules, которые определяют, какие машины будут реплицироваться, а какие нет. Делается это с помощью движка политик storage policy-based management (SPBM) для ВМ и их VMDK-дисков:
Как некоторые из вас знают,
у компаний VMware и Microsoft есть совместное предложение облачных услуг Azure VMware Solution (AVS). Платформа AVS предоставляет клиентам облачной IaaS-инфраструктуры Azure полный комплект облачных решений VMware стека SDDC, таких как vSphere, vSAN, NSX-T и других, которые бесшовно интегрированы в Microsoft Azure. Все это позволяет крупным компаниям строить гибридные инфраструктуры с единым набором инфраструктурных решений между онпремизной площадкой и облаком Azure.
Не так давно это облако стало доступно и на базе VDI-решения VMware Horizon.
Недавно VMware выпустила 3 интересных лабораторных работы (они же Hands-On Labs, HoL), пройдя которые вы сможете узнать об этом решении больше и пройти через выполнение различных задач в интерфейсах облака AVS.
Эта лаба будет полезна тем, кто хочет больше узнать об использовании облака AVS как Disaster Recovery решения, которое возьмет на себя нагрузку в случае сбоя в собственном облаке на базе VMware vSphere. Модуль также длится 30 минут:
Это уже довольно серьезная лабораторная работа, состоящая из 5 модулей по 15 минут, где рассматриваются различные аспекты построения сетей SD-WAN и архитектуры Virtual Cloud Network, а также перестроения существующих сетей для работы этих технологий.
Полный список доступных лабораторных работ VMware Hands-On Labs можно посмотреть здесь.
Таги: VMware, Azure, AVS, Cloud, HoL, Labs, Update, Microsoft
Очередная интересная штука появилась на сайте проекта VMware Labs - утилита NUMA Observer, которая позволяет обнаружить виртуальные машины с перекрытием использования NUMA-узлов на хостах ESXi. При работе с тяжелыми нагрузками, требовательными к Latency, администраторы часто создают affinity-правила по привязке виртуальных машин к NUMA-узлам и ядрам CPU, чтобы они работали быстрее, с наименьшими задержками.
Но после сбоев и неполадок механизм VMware HA, восстанавливающий виртуальные машины на других хостах, может нарушить эту конфигурацию - там могут быть ВМ с уже привязанными NUMA-узлами, в результате чего возникнет перекрытие (overlap), которое полезно своевременно обнаружить.
С помощью NUMA Observer можно не только обнаруживать перекрытия по использованию ядер CPU и NUMA-узлов со стороны виртуальных машин, но и собирать статистики по использованию памяти дальнего узла и недостатке CPU-ресурсов (метрика CPU Ready). После анализа конфигураций и использования ресурсов, утилита генерирует алерты, которые администратор может использовать как исходные данные при настройке новой конфигурации NUMA-узлов.
Скачать NUMA Observer
можно по этой ссылке. После установки сервис доступен через веб-консоль по адресу localhost:8443. Для его работы потребуется Java 8.
Как вы знаете, в кластере отказоустойчивости VMware HA есть Primary и Secondary хосты серверов ESXi. Первые отвечают за управление кластером и восстановление виртуальных машин, а вторые – только за исполнение операций и рестарт ВМ. Недавно мы, кстати, писали о том, как сделать хост VMware vSphere Primary (он же Master) в кластере HA, а сегодня расскажем о том, какие события происходят на этих хостах в случае отказа хоста (именно полного отказа, а не при недоступности, например, его в сети).
Как пишет Дункан Эппинг, если отказывает хост Secondary, то происходят следующие вещи, начиная с времени T0:
T0 – происходит отказ хоста и недоступность виртуальных машин (например, отключение питания, завис ESXi и т.п.)
T+3 секунды – хост Primary начинает отслеживать хартбиты на хранилище в течение 15 секунд
T+10 секунд – хост помечается как unreachable и Primary хост начинает пинговать его Management Network (постоянно в течение 5 секунд)
T+15 секунд – если на датасторе на настроены хартбиты, то хост помечается как «мертвый», и начинается процесс восстановления виртуальных машин
Либо если настроены хартбиты, но их нет, то через T+18 секунд хост помечается как «мертвый», и начинается процесс восстановления виртуальных машин
В случае с отказом Primary хоста все немного дольше и сложнее, так как кластеру нужно определиться с новым Primary узлом и восстановить/перенастроить себя. Тут происходит следующее:
T0 – происходит отказ хоста и недоступность виртуальных машин (например, отключение питания, завис ESXi и т.п.)
T+10 секунд – начинаются выборы нового Primary хоста в кластере
T+25 секунд - выбор хоста Primary сделан и он читает список виртуальных машин, а также ждет, пока Secondary хосты сообщат о своих виртуальных машинах
T+35 секунд – старый хост Primary помечается как unreachable
T+50 секунд – хост помечается как «мертвый», и начинается процесс восстановления виртуальных машин согласно списку нового Primary
Надо помнить, что это все времена начала процессов, но не их завершения. Например, если процесс восстановления начинается через 15 секунд, то нужно время, чтобы найти место для виртуальной машины на новом хосте и запустить ее там – а вот это время рассчитать невозможно.
Дункан Эппинг написал интересный пост о том, что в кластере VMware HA есть возможность сделать хостам ESXi такую настройку, чтобы они выбирались как Primary при конфигурации/реконфигурации кластера. Это может оказаться полезным, например, в растянутом (Stretched) кластере, когда вам важно, чтобы Primary-хосты находились на основной площадке с целью ускорения процесса восстановления после сбоя (речь идет о 2-3 секундах в большинстве случаев, но для некоторых инфраструктур это может быть критично).
Пост этот актуален еще и потому, что настройки несколько изменились, начиная с VMware vSphere 7 Update 1, поэтому информация об этом может быть полезна для администраторов.
Прежде всего, в статье VMware KB 80594 рассказывается о том, какие настройки были изменены в механизме VMware FDM (он же HA). Самое главное, что до vCenter 7 Update 1 настройки хранились в файле /etc/opt/vmwware/fdm/fdm.cfg, теперь же они переехали в ConfigStore, работать с которым нужно путем импорта и экспорта json-файлов конфигурации.
Вот, кстати, интересующая нас табличка с изменениями параметров Advanced Settings в FDM:
Нас здесь интересует настройка node_goodness, большое численное значение которой и определяет, будет ли данный узел выбран как Primary (ранее в HA он также назывался Master).
Итак, Дункан показывает, как можно экспортировать расширенные настройки из ConfigStore:
configstorecli config current get -g cluster -c ha -k fdm
{
"mem_reservation_MB": 200,
"memory_checker_time_in_secs": 0
}
Все это можно также экспортировать в json-файл командой:
configstorecli config current get -g cluster -c ha -k fdm > test.json
Далее добавляем в этот json параметр node_goodness с большим значением, например, 10000000:
На ресурсе интерактивных лабораторных работ VMware Hands-On Labs появилось 2 лабы, посвященных сервису VMware Skyline. Напомним, что Skyline - это проактивная технология VMware для предоставления расширенной технической поддержки некоторым клиентам для Enterprise-продуктов с целью предотвратить возникновение проблем в будущем на базе анализа текущего состояния виртуальной среды.
Лабораторные работы, как ни что другое, помогут вам понять, нужен ли вам тот или иной продукт VMware на самом деле или нет.
Вот небольшое видео о том, как зарегистрироваться на ресурсе Hands-on Labs, найти эти лабораторные работы и приступить к их выполнению:
Работает это в любом браузере, не требует никаких установок, но главное - полностью бесплатно. Посмотреть весь каталог HoL можно по этой ссылке. Кстати, там уже набралось более 120 лабораторных работ, в создании которых принимало участие более двух сотен инженеров.
Вчера мы писали о новых возможностях обновленной платформы виртуализации VMware vSphere 7 Update 2, а сегодня расскажем о вышедшем одновременно с ней обновлении решения для создания отказоустойчивых кластеров хранилищ VMware vSAN 7 Update 2.
Нововведения сосредоточены в следующих областях:
Давайте посмотрим, что именно нового в vSAN 7 U2:
Улучшения масштабируемости
HCI Mesh Compute Clusters
Теперь в дополнение к анонсированной в vSphere 7 Update 1 топологии HCI Mesh для удаленного доступа к хранилищам vSAN появилась технология HCI Mesh Compute Clusters, которая позволяет иметь вычислительный кластер vSphere/vSAN без собственных хранилищ, использующий хранилища удаленных кластеров.
Самое интересное, что эти кластеры не нуждаются в лицензиях vSAN, вы можете использовать обычные лицензии vSphere.
Также такие кластеры vSAN могут использовать политики хранилищ, в рамках которых можно получить такие сервисы, как дедупликацию / компрессию или шифрование Data-at-rest:
Также было увеличено число хостов ESXi, которые могут соединяться с удаленным датастором, до 128.
Небольшое видео о том, как создать HCI Mesh Compute Cluster:
Улучшение файловых служб
Службы vSAN file services теперь поддерживают растянутые (stretched) кластеры и двухузловые конфигурации, что позволяет использовать их для ROBO-сценариев.
Улучшения растянутых кластеров
Растянутые кластеры vSAN теперь обрабатывают не только различные сценарии сбоев, но и условия восстановления, которые были определены механизмом DRS до наступления события отказа. DRS будет сохранять ВМ на той же площадке до того, как данные через inter-site link (ISL) будут полностью синхронизированы после восстановления кластера, после чего начнет перемещать виртуальные машины в соответствии со своими правилами. Это повышает надежность и позволяет не загружать ISL-соединение, пока оно полностью не восстановилось.
Технология vSAN over RDMA
В vSAN 7 Update 2 появилась поддержка технологии RDMA over Converged Ethernet version 2 (RCoEv2). Кластеры автоматически обнаруживают поддержку RDMA, при этом оборудование должно находиться в списке совместимости VMware Hardware Compatibility Guide.
Улучшения производительности
В vSAN 7 U2 была оптимизирована работа с RAID 5/6 в плане использования CPU. Также была улучшена производительность яруса буффера. Это позволяет снизить CPU cost per I/O.
Кроме того, были сделаны оптимизации для процессоров AMD EPYC (см. тут).
Улучшения для задач AI and Developer Ready
Здесь появилось 2 основных улучшения:
S3-совместимое объектное хранилище для задач AI/ML и приложений Cloud Native Apps.
На платформе vSAN Data Persistence platform теперь поддерживаются компоненты Cloudian HyperStore и MinIO Object Storage. Пользователи могут потреблять S3-ресурсы для своих AI/ML нагрузок без необходимости долгой настройки интеграций.
Улучшения Cloud Native Storage в vSphere и vSAN
Теперь Cloud Native Storage лучше поддерживает stateful apps на платформе Kubernetes. Также vSAN предоставляет простые средства для миграции с устаревшего vSphere Cloud Provider (vCP) на Container Storage Interface (CSI). Это позволит иметь персистентные тома Kubernetes на платформе vSphere и расширять их по мере необходимости без прерывания обслуживания.
Улучшения безопасности
Службы vSphere Native Key Provider Services
Это механизм, который позволяет использовать защиту data-at-rest, такую как vSAN Encryption, VM Encryption и vTPM прямо из коробки. Также для двухузловых конфигураций и Edge-топологий можно использовать встроенный KMS-сервис, который работает с поддержкой ESXi Key Persistence.
Средства для изолированных окружений
VMware предоставляет Skyline Health Diagnostics tool, который позволяет самостоятельно определить состояние своего окружения в условиях изоляции от интернета. Он сканирует критические компоненты на проблемы и выдает рекомендации по их устранению со ссылками на статьи базы знаний VMware KB.
Улучшения Data In Transit (DIT) Encryption
Здесь появилась валидация FIPS 140-2 криптографического модуля для DIT-шифрования.
Упрощение операций
Улучшения vLCM
Для vSphere Lifecycle Manager появились следующие улучшения:
vLCM поддерживает системы Hitachi Vantara UCP-HC и Hitachi Advanced Servers, а также серверы Dell 14G, HPE10G и Lenovo ThinkAgile.
При создании кластера можно указать образ существующего хоста ESXi.
Улучшения защиты данных
При сбое и недоступности хранилищ хост ESXi, который понял, что произошла авария, начинает записывать дельта-данные с этого момента не только на хранилище, где хранится активная реплика, но и в дополнительное хранилище, чтобы обеспечить надежность данных, создаваемых во время сбоя. Ранее эта технология применялась для запланированных операций обслуживания.
Поддержка Proactive HA
vSAN 7 Update 2 теперь поддерживает технологию Proactive HA, которая позволяет проактивно смигрировать данные машин на другой хост ESXi.
Улучшения мониторинга
Здесь появились новые метрики и хэлсчеки, которые дают больше видимости в инфраструктуре коммутаторов, к которой подключены хосты vSAN. На физическом уровне появились дополнительные метрики, такие как CRC, carrier errors, transmit и receive errors, pauses. Также для новых метрик были добавлены health alarms, которые предупредят администратора о приближении к пороговым значениям.
Улучшения vSphere Quick Boot
Здесь появилась техника ESXi Suspend-to-Memory, которая позволяет еще проще обновлять хосты ESXi. Она доступна в комбинации с технологией ESXi Quick Boot. Виртуальные машины просто встают на Suspend в памяти ESXi, вместо эвакуации с хоста, а потом ядро гипервизора перезапускается и хост обновляется.
Скачать VMware vSAN 7 Update 2 в составе vSphere 7 Update 2 можно по этой ссылке. Release Notes доступны тут.
Бонус-видео обзора новых фичей от Дункана Эппинга:
Таги: VMware, vSAN, Update, ESXi, vSphere, Storage, HA, DR, VMachines
На сайте проекта VMware Labs появилось обновление утилиты VMware Event Broker Appliance (VEBA) v0.5. Напомним, что это решение, которое позволяет пользователям создавать сценарии автоматизации на базе событий, генерируемых в VMware vCenter Service. Например, VEBA может выполнять такие рабочие процессы, как автоматическое привязывание нужного тэга ко вновь создаваемой виртуальной машине. Работает он по модели "If This Then That". О версии VEBA 0.3, вышедшей весной этого года, мы писали вот тут.
Давайте посмотрим, что нового появилось в продукте, начиная с версии 0.3 и вплоть до вышедшей на днях версии 0.5:
Новый интерфейс VEBA Direct Console UI (DCUI)
Новые примеры функций Incident Management
Новый пример функции на Golang
Возможность развертывания VEBA в существующем кластере Kubernetes (см. тут)
Обновление базовой ОС на последний релиз Photon OS 3.0 Rev2
Сетевой провайдер (CNI) контейнеров Weave заменен на Antrea
Поддержка кастомизации Docker bridge network (default: 172.17.0.1/16) через свойство OVF-шаблона
Возможность мониторинга виртуального модуля VEBA через vRealize Operations (см. тут)
На сайте проекта VMware Hans-on Labs (HOL) появились две новые лабораторные работы, посвященные новой версии продукта для создания отказоустойчивых хранилищ VMware vSAN 7.
Лабораторные работы VMware HoL позволяют освоить работу с различными продуктами и технологиями, проходя по шагам интерфейса. Такой способ отлично подходит для обучения работе с новыми версиями решений без необходимости их развертывания.
Напомним, что в последнее время мы уже писали об обновлениях лабораторных работ:
Хранилища vSAN Cloud Native Storage (CNS) для контейнеров кластеров Kubernetes
Мониторинг состояния, доступных емкостей и производительности
Облуживание и управление жизненным циклом хранилищ и виртуальных машин
Шифрование и безопаность платформы
Вторая лабораторная работа посвящена мастеру QuickStart для пошагового создания кластера хранилищ vSAN, с помощью которого можно быстро освоить его основные настройки и конфигурации:
Некоторое время назад мы писали о новых возможностях платформы виртуализации VMware vSphere 7, среди которых мы вкратце рассказывали о нововведениях механизма динамического распределения нагрузки на хосты VMware DRS. Давайте взглянем сегодня на эти новшества несколько подробнее.
Механизм DRS был полностью переписан, так как его основы закладывались достаточно давно. Раньше DRS был сфокусирован на выравнивании нагрузки на уровне всего кластера хостов ESXi в целом, то есть бралась в расчет загрузка аппаратных ресурсов каждого из серверов ESXi, на основании которой рассчитывались рекомендации по миграциям vMotion виртуальных машин:
При этом раньше DRS запускался каждые 5 минут. Теперь же этот механизм запускается каждую минуту, а для генерации рекомендаций используется механизм VM DRS Score (он же VM Hapiness). Это композитная метрика, которая формируется из 10-15 главных метрик машин. Основные метрики из этого числа - Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness. Расчеты по памяти теперь основываются на Granted Memory вместо стандартного отклонения по кластеру.
Мы уже рассказывали, что в настоящее время пользователи стараются не допускать переподписку по памяти для виртуальных машин на хостах (Memory Overcommit), поэтому вместо "Active Memory" DRS 2.0 использует параметр "Granted Memory".
VM Happiness - это основной KPI, которым руководствуется DRS 2.0 при проведении миграций (то есть главная цель всей цепочки миграций - это улучшить этот показатель). Также эту оценку можно увидеть и в интерфейсе:
Как видно из картинки, DRS Score квантуется на 5 уровней, к каждому из которых относится определенное количество ВМ в кластере. Соответственно, цель механизма балансировки нагрузки - это увеличить Cluster DRS Score как агрегированный показатель на уровне всего кластера VMware HA / DRS.
Кстати, на DRS Score влияют не только метрики, касающиеся производительности. Например, на него могут влиять и метрики по заполненности хранилищ, привязанных к хостам ESXi в кластере.
Надо понимать, что новый DRS позволяет не только выровнять нагрузку, но и защитить отдельные хосты ESXi от внезапных всплесков нагрузки, которые могут привести виртуальные машины к проседанию по производительности. Поэтому главная цель - это держать на высоком уровне Cluster DRS Score и не иметь виртуальных машин с низким VM Hapiness (0-20%):
Таким образом, фокус DRS смещается с уровня хостов ESXi на уровень рабочих нагрузок в виртуальных машинах, что гораздо ближе к требованиям реального мира с точки зрения уровня обслуживания пользователей.
Если вы нажмете на опцию View all VMs в представлении summary DRS view, то сможете получить детальную информацию о DRS Score каждой из виртуальных машин, а также другие важные метрики:
Ну и, конечно же, на улучшение общего DRS Score повлияет увеличения числа хостов ESXi в кластере и разгрузка его ресурсов.
Кстати, ниже приведен небольшой обзор работы в интерфейсе нового DRS:
Еще одной важной возможностью нового DRS является функция Assignable Hardware. Многие виртуальные машины требуют некоторые аппаратные возможности для поддержания определенного уровня производительности, например, устройств PCIe с поддержкой Dynamic DirectPath I/O или NVIDIA vGPU. В этом случае теперь DRS позволяет назначить профили с поддержкой данных функций для первоначального размещения виртуальных машин в кластере.
В видео ниже описано более подробно, как это работает:
Ну и надо отметить, что теперь появился механизм Scaleable Shares, который позволяет лучше выделять Shares в пуле ресурсов с точки зрения их балансировки. Если раньше высокий назначенный уровень Shares пула не гарантировал, что виртуальные машины этого пула получат больший объем ресурсов на практике, то теперь это может использоваться именно для честного распределения нагрузки между пулами.
Этот механизм будет очень важным для таких решений, как vSphere with Kubernetes и vSphere Pod Service, чтобы определенный ярус нагрузок мог получать необходимый уровень ресурсов. Более подробно об этом рассказано в видео ниже:
Недавно мы, говоря о главных анонсах конференции VMworld 2019, забыли рассказать об одном из самых главных - релизе продукта для управления и мониторинга виртуальной инфраструктуры VMware vRealize Operations 8.0. Напомним, что о новых возможностях vRealize Operations 7.5 мы писали вот тут. Надо сказать, что несмотря на то, что vROPs 8.0 бы анонсирован еще в августе этого года...
На конференции VMworld 2019, которая недавно прошла в Сан-Франциско, было представлено так много новых анонсов продуктов и технологий, что мы не успеваем обо всех рассказывать. Одной из самых интересных новостей стала информация про новую версию распределенного планировщика ресурсов VMware Distributed Resource Scheduler (DRS) 2.0. Об этом было рассказано в рамках сессии "Extreme Performance Series: DRS 2.0 Performance Deep Dive (HBI2880BU)", а также про это вот тут написал Дункан Эппинг.
Надо сказать, что технология DRS, позволяющая разумно назначать хосты ESXi для виртуальных машин и балансировать нагрузку за счет миграций ВМ посредством vMotion между серверами, была представлена еще в 2006 году. Работает она без кардинальных изменений и по сей день (13 лет!), а значит это очень востребованная и надежная штука. Но все надо когда-то менять, поэтому скоро появится и DRS 2.0.
Если раньше основным ресурсом датацентров были серверы, а значит DRS фокусировался на балансировке ресурсов в рамках кластера серверов ESXi, то теперь парадигма изменилась: основной элемент датацентра - это теперь виртуальная машина с приложениями, которая может перемещаться между кластерами и физическими ЦОД.
Сейчас технология DRS 2.0 находится в статусе Technical Preview, что значит, что никто не гарантирует ее присутствие именно в таком виде в будущих продуктах VMware, кроме того нет и никаких обещаний по срокам.
В целом, изменилось 3 основных момента:
Появилась новая модель затраты-преимущества (cost-benefit model)
Добавлена поддержка новых ресурсов и устройств
Все стало работать быстрее, а инфраструктура стала масштабируемее
Давайте посмотрим на самое интересное - cost-benefit model. Она вводит понятие "счастья виртуальной машины" (VM Happiness) - это композитная метрика, которая формируется из 10-15 главных метрик машин. Основные из этого числа - Host CPU Cache Cost, VM CPU Ready Time, VM Memory Swapped и Workload Burstiness.
VM Happiness будет основным KPI, которым будет руководствоваться DRS 2.0 при проведении миграций (то есть цель - улучшить этот показатель). Также эту оценку можно будет увидеть и в интерфейсе. Помимо этого, можно будет отслеживать этот агрегированный показатель и на уровне всего кластера VMware HA / DRS.
Второй важный момент - DRS 2.0 будет срабатывать каждую минуту, а не каждые 5 минут, как это происходит сейчас. Улучшение связано с тем, что раньше надо было снимать "снапшот кластера", чтобы вырабатывать рекомендации по перемещению виртуальных машин, а сейчас сделан простой и эффективный механизм - VM Happiness.
Отсюда вытекает еще одна полезная функциональность - возможность изменять интервал опроса счастливости виртуальных машин - для стабильных нагрузок это может быть, например, 40-60 минут, а для более непредсказуемых - 15-20 или даже 5.
Еще одна интересная фича - возможность проводить сетевую балансировку нагрузки при перемещении машин между хостами (Network Load Balancing). Да, это было доступно и раньше, что было вторичной метрикой при принятии решений о миграции посредством DRS (например, если с ресурсами CPU и памяти было все в порядке, то сетевая нагрузка не учитывалась). Теперь же это полноценный фактор при принятии самостоятельного решения для балансировки.
Вот пример выравнивания такого рода сетевой нагрузки на виртуальные машины на разных хостах:
Модель cost-benefit также включает в себя возможности Network Load Balancing и устройства PMEM. Также DRS 2.0 будет учитывать и особенности аппаратного обеспечения, например, устройства vGPU. Кстати, надо сказать, что DRS 2 будет также принимать во внимание и характер нагрузки внутри ВМ (стабильна/нестабильна), чтобы предотвратить "пинг-понг" виртуальных машин между хостами ESXi. Кстати, для обработки таких ситуаций будет использоваться подход "1 пара хостов source-destination = 1 рекомендация по миграции".
Также мы уже рассказывали, что в настоящее время пользователи стараются не допускать переподписку по памяти для виртуальных машин на хостах (memory overcommit), поэтому вместо "active memory" DRS 2.0 будет использовать параметр "granted memory".
Ну и был пересмотрен механизм пороговых значений при миграции. Теперь есть следующие уровни работы DRS для различных типов нагрузок:
Level 1 – балансировка не работает, происходит только выравнивание нагрузки в моменты, когда произошло нарушение правил DRS.
Level 2 – работает для очень стабильных нагрузок.
Level 3 – работает для стабильных нагрузок, но сфокусирован на метрике VM happiness (включено по умолчанию).
Level 4 – нагрузки со всплесками (Bursty workloads).
Level 5 – динамические (Dynamic) нагрузки с постоянными изменениями.
В среднем же, DRS 2.0 обгоняет свою первую версию на 5-10% по быстродействию, что весьма существенно при больших объемах миграций. При этом VMware понимает, что новый механизм DRS второй версии может родить новые проблемы, поэтому в любой момент можно будет вернуться к старому алгоритму балансировки с помощью расширенного параметра кластера FastLoadBalance=0.
По срокам доступности технологии DRS 2.0 информации пока нет, но, оказывается, что эта технология уже почти год работает в облаке VMware Cloud on AWS - и пока не вызывала нареканий у пользователей. Будем следить за развитием событий.
Многие администраторы платформы VMware vSphere очень часто интересуются вопросом замены сертификатов для серверов ESXi в целях обеспечения безопасности. Как правило, это просто инструкции, которые не дают понимания - а зачем именно нужно менять эти сертификаты.
Недавно VMware выпустила интересную статью на тему сертификатов в vSphere и других продуктах, приведем ниже основные выдержки из нее.
1. Сертификаты - это вопрос доверия и шифрования.
При соединении с различными веб-консолями компонентов инфраструктуры VMware vSphere используется протокол HTTPS, где S означает "Secure". Инфраструктура SSL, а точнее ее последователь Transport Layer Security (TLS), использует известный в криптографии принцип открытого и закрытого ключей, который позволяет узлам, доверяющим друг другу безопасно обмениться информацией по шифрованному каналу.
TLS развивается по следующему пути:
Версия 1.0 имеет уязвимости, он небезопасен и больше не должен использоваться.
Версия 1.1 не имеет таких уязвимостей, как 1.0, но использует такие алгоритмы шифрования, как MD5 и SHA-1, которые больше не считаются безопасными.
Версия 1.2 добавляет шифрование AES, которое работает быстро и не использует небезопасные методы, сам же алгоритм использует SHA-256. На текущий момент это стандарт TLS.
Версия 1.3 не содержит слабых точек и добавляет возможности увеличения скорости соединения, этот стандарт скоро будет использоваться.
Если вы используете сертификаты vSphere, то независимо от того, какие они (самоподписанные или выданные центром сертификации) - общение между компонентами виртуальной инфраструктуры будет вестись посредством TLS с надежным шифрованием. Вопрос сертификатов тут - это всего лишь вопрос доверия: какому объекту, выпустившему сертификат, вы доверяете - это и есть Центр сертификации (он же Certificate Authority, CA).
Многие крупные компании, имеющие определенный вес (например, Microsoft) сами являются Центрами сертификации, а некоторые компании используют службы Microsoft Active Directory Certificate Services, чтобы встроить собственные CA в операционную систему и браузеры (импортируют корневые сертификаты), чтобы "научить" их доверять этим CA.
2. В VMware vSphere сертификаты используются повсеместно.
Как правило, они используются для трех целей:
Сертификаты серверов ESXi, которые выпускаются для управляющих интерфейсов на всех хост-серверах.
"Машинные" сертификаты SSL для защиты консолей, с которыми работает человек - веб-консоль vSphere Client, страница логина SSO или Platform Service Controllers (PSCs).
"Solution"-сертификаты, используемые для защиты коммуникаций со сторонними к платформе vSphere продуктам, таким как vRealize Operations Manager, vSphere Replication и другим.
Полный список компонентов, где vSphere использует сертификаты, приведен вот тут.
3. vSphere имеет собственный Центр сертификации.
Платформа vSphere из коробки поставляется с собственным CA, который используется для коммуникации между компонентами. Называется он VMware Certificate Authority (VMCA) и полностью поддерживается для vSphere как с внешним PSC, так и для vCenter Server Appliance (vCSA) со встроенным PSC.
Как только вы добавляете хост ESXi в окружение vCenter, то VMCA, работающий на уровне vCenter, выпускает новый сертификат на этот ESXi и добавляет его в хранилище сертификатов. Такая же штука происходит, когда вы настраиваете интеграцию, например, с решениями vRealize Operations Manager или VMware AppDefense.
Надо понимать, что CA от VMware - это всего лишь решение для защищенной коммуникации между серверами, которое поставляется из коробки. Ваше право - доверять этой модели или нет.
4. Есть 4 способа внедрить инфраструктуру сертификатов на платформе vSphere.
Вот они:
Использовать самоподписанные сертификаты VMCA. Вы можете просто скачать корневые сертификаты с веб-консоли vCenter, импортировать их в операционную систему клиентских машин. В этом случае при доступе к веб-консоли, например, vSphere Client у вас будет отображаться зеленый замочек.
VMCA можно сделать подчиненным или промежуточным (subordinate/ intermediate) центром сертификации, поставив его посередине между CA и конечными хостами, что даст дополнительный уровень сложности и повысит вероятность ошибки в настройке. VMware не рекомендует так делать.
Отключить VMCA и использовать собственные сертификаты для любых коммуникаций. Ваш ответственный за сертификаты должен нагенерировать запросы Certificate Signing Requests (CSR) для всех компонентов. Эти CSR-запросы вы отсылаете с CA, которому вы доверяете, получаете их подписанными, после чего устанавливаете их в ручном режиме. Это отнимает время и чревато ошибками.
Использовать гибридный подход - для хостов ESXi в их коммуникации с vCenter использовать самоподписанные VMCA сертификаты, а для веб-консолей vSphere Client и прочих использовать перевыпущенные сертификаты, которые надо установить на сервере vCenter и хостах, с которых будет управляться инфраструктура через браузер (тогда в нем появится зеленый замочек). Это самый рекомендуемый VMware вариант использования сертификатов.
5. Enterprise-сертификаты - тоже самоподписанные.
Подумайте - самоподписанными являются не только сертификаты VMCA, но и ваши корпоративные сертификаты. Если вы выпускаете эти сертификаты только на уровне своей компании, то у вас 2 точки потенциального недоверия - сторона, выпустившая сертификаты у вас в компании, а также, собственно, сам VMCA. Такая схема создает дополнительный уровень сложности администрирования, а также нарушения безопасности.
6. Не создавайте промежуточный Центр сертификации.
Если вы создаете intermediate CA (он же subordinate CA) для VMCA, превращая его в посредника, вы создаете потенциальную опасность для виртуальной инфраструктуры - если кто-то получает доступ к корпоративному центру сертификации и его парам ключей, то он может навыпускать любых сертификатов от имени VMCA и перехватывать потом любые коммуникации.
7. Можно изменять информацию для самоподписанных сертификатов CA.
С помощью утилиты Certificate Manager utility вы можете сгенерировать новый VMCA с необходимой информацией о вашей организации внутри него. Эта утилита перевыпустит все сертификаты и заменит их на всех хостах виртуальной инфраструктуры. Это хорошая опция для гибридной модели. Кстати, вы можете менять даты устаревания сертификатов, если дефолтные вас не устраивают.
8. Тестируйте инфраструктуру сертификатов перед внедрением.
Вы можете развернуть виртуальную инфраструктуру и провести все эксперименты с сертификатами в виртуальной среде, где вы можете использовать виртуальные (nested) серверы ESXi. Приятная штука в том, что вы можете создавать снапшоты виртуальных машин, а значит в случае чего - быстро откатитесь на рабочий вариант. Еще одна среда для экспериментов - это облачная инфраструктура VMware Hands-on Labs, где можно безопасно ставить любые эксперименты.
Делайте резервную копию вашего vCenter и PSC на уровне файлов через веб-консоль VAMI. Также утилитой Certificate Manager можно скопировать старый набор сертификатов перед развертыванием новых (но только один набор сертификатов, учитывайте это). Также эта процедура полностью поддерживается со стороны VMware Global Support Services.
10. Понимайте, зачем вы заморачиваетесь с заменой сертификатов.
Ответьте для себя на несколько вопросов:
Стоит ли иконка зеленого замочка в браузере всех этих заморочек?
Нужно ли всем видеть этот замочек или только команде администрирования vSphere?
Почему вы доверяете vCenter для управления всем в виртуальной инфраструктуре, но не доверяете VMCA?
В чем отличие самоподисанного сертификата вашего предприятия от самоподписанного сертификата VMCA?
Действительно ли комплаенс требует от вас кастомных CA-сертификатов?
Какова будет цена процедур по замене сертификатов в инфраструктуре vSphere во времени и деньгах?
Увеличивает или уменьшает риск итоговое решение и почему конкретно?
Как знают почти все администраторы платформы VMware vSphere, для кластеров VMware HA/DRS есть такой режим работы, как Enhanced vMotion Compatibility (EVC). Нужен он для того, чтобы настроить презентацию инструкций процессора (CPU) хостами ESXi так, чтобы они в рамках кластера соответствовали одному базовому уровню (то есть все функции процессоров приводятся к минимальному уровню с набором инструкций, которые гарантированно есть на всех хостах).
Ввели режим EVC еще очень давно, чтобы поддерживать кластеры VMware vSphere, где стоят хосты с процессорами разных поколений. Эта ситуация случается довольно часто, так как клиенты VMware строят, например, кластер из 8 хостов, а потом докупают еще 4 через год-два. Понятно, что процессоры уже получаются другие, что дает mixed-окружение, где по-прежнему надо перемещать машины между хостами средствами vMotion. И если набор презентуемых инструкций CPU будет разный - двигать машины между хостами будет проблематично.
EVC маскирует инструкции CPU, которые есть не на всех хостах, от гостевых ОС виртуальных машин средствами интерфейса CPUID, который можно назвать "API для CPU". В статье VMware KB 1005764 можно почитать о том, как в кластере EVC происходит работа с базовыми уровнями CPU, а также о том, какие режимы для каких процессоров используются.
Надо отметить, что согласно опросам VMware, режим кластера EVC используют более 80% пользователей:
В VMware vSphere 6.7 появились механизмы Cross-Cloud Cold и Hot Migration, которые позволяют переносить нагрузки в онлайн и офлайн режиме между облаками и онпремизной инфраструктурой.
Когда это происходит, виртуальной машине приходится перемещаться между хостами с разными наборами инструкций процессора. Поэтому, в связи с распространением распределенных облачных инфраструктур, в vSphere появилась технология Per-VM EVC, которая позволяет подготовить виртуальную машину к миграции на совершенно другое оборудование.
По умолчанию, при перемещении машины между кластерами она теряет свою конфигурацию EVC, но в конфигурации ВМ можно настроить необходимый базовый уровень EVC, чтобы он был привязан к машине и переезжал вместе с ней между кластерами:
Обратите внимание, что Per-VM EVC доступна только, начиная с vSphere 6.7 и версии виртуального железа Hardware Version 14. Эта конфигурация сохраняется в vmx-файле (потому и переезжает вместе с машиной) и выглядит следующим образом:
Некоторые пользователи не включают EVC, так как покупают унифицированное оборудование, но VMware рекомендует включать EVC в кластерах со старта, так как, во-первых, никто не знает, какое оборудование будет докупаться в будущем, а, во-вторых, так будет легче обеспечивать миграцию виртуальных машин между облачными инфраструктурами.
Основная причина, по которой не включают EVC - это боязнь того, что поскольку машины не будут использовать весь набор инструкций CPU (особенно самых последних), то это даст снижение производительности. Поэтому VMware написала целый документ "Impact of Enhanced vMotion Compatibility on Application Performance", где пытается доказать, что это не сильно влияет на производительность. Вот, например, производительность Oracle на выставленных базовых уровнях для разных поколений процессоров (в документе есть еще много интересных графиков):
Чтобы включить EVC на базе виртуальной машины, нужно ее выключить, после чего настроить нужный базовый уровень. Для автоматизации этого процесса лучше использовать PowerCLI, а сама процедура отлично описана в статье "Configuring Per-VM EVC with PowerCLI".
Для того, чтобы выяснить, какие базовые уровни EVC выставлены для виртуальных машин в кластере, можно использовать следующий сценарий PowerCLI:
Get-VM | Select Name,HardwareVersion,
@{Name='VM_EVC_Mode';Expression={$_.ExtensionData.Runtime.MinRequiredEVCModeKey}},
@{Name='Cluster_Name';Expression={$_.VMHost.Parent}},
@{Name='Cluster_EVC_Mode';Expression={$_.VMHost.Parent.EVCMode}} | ft
Это даст примерно следующий результат (надо помнить, что отчет будет сгенерирован только для VM hardware version 14 и позднее):
В примере выше одна машина отличается от базового уровня хостов, но в данном случае это поддерживаемая конфигурация. Проблемы начинаются, когда машина использует более высокий базовый уровень CPU, чем его поддерживает хост ESXi. В этом случае при миграции vMotion пользователь получит ошибку:
Понять максимально поддерживаемый режим EVC на хосте можно с помощью команды:
В целом тут совет такой - включайте режим Enhanced vMotion Compatibility (EVC) в кластерах и для виртуальных машин VMware vSphere сейчас, чтобы не столкнуться с неожиданными проблемами в будущем.
Многие из вас, конечно же, прекрасно знают, как работает механизм VMware HA на платформе vSphere. Но для тех из вас, кто подзабыл, Дункан написал пост о том, через какой интерфейс VMkernel идет этот трафик.
Так вот, хартбиты механизма HA пойдут через тот vmk-интерфейс, на котором в vSphere Client отмечена галочка Management, как на картинке:
Надо понимать, что этот пункт, хоть и называется Management, имеет отношение только к HA-трафику. Это означает, что если галочка не отмечена, то через этот интерфейс все равно можно будет подключиться по протоколу SSH, а также присоединить хост ESXi к серверу управления VMware vCenter, используя этот IP-адрес.
Так что Management - это не про управление, а только про HA. Это касается только обычной виртуальной инфраструктуры, а вот в кластере vSAN трафик HA идет по выделенной под vSAN сети автоматически.

 RSS
RSS